Some SpiderMonkey optimizations in Firefox Quantum
MozillaA few weeks ago we released Firefox 57, also known as Firefox Quantum. I work on SpiderMonkey performance and this year I spent a lot of time analyzing profiles and optimizing as many things as possible.
I can't go through all SpiderMonkey performance improvements here: this year alone I landed almost 500 patches (most of them performance related, most of them pretty boring) and other SpiderMonkey hackers have done excellent work in this area as well. So I just decided to focus on some of the more interesting optimizations I worked on in 2017. Most of these changes landed in Firefox 55-57, some of them will ship in Firefox 58 or 59.
shift/unshift optimizations
Array.prototype.shift removes the first element from an array. We used to implement this by moving all other elements in memory, so shift() had O(n) performance. When JS code uses arrays as queues, it was easy to get quadratic behavior (outlook.com did something like this):
while (arr.length > 0)
foo(arr.shift());
The situation was even worse for us when we were in the middle of an incremental GC (due to pre-barriers).
Instead of moving the elements in memory, we can now use pointer arithmetic to make the object point to the second element (with some bookkeeping for the GC) and this is an order of magnitude faster when there are many elements. I also optimized unshift and splice to take advantage of this shifted-elements optimization. For instance, unshift can now reserve space for extra elements at the start of the array, so subsequent calls to unshift will be very fast.
While working on this I noticed some other engines have a similar optimization, but it doesn't always work (for example when the array has many elements). In SpiderMonkey, the shifted-elements optimization fits in very well architecturally and we don't have such performance cliffs (as far as I know!).
Regular expressions
RegExp objects can now be nursery allocated. We can now also allocate them directly from JIT code. These changes improved some benchmarks a lot (the orange line is Firefox):
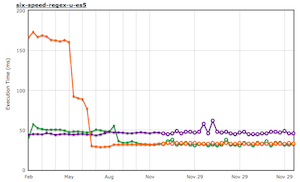
While working on this, I also moved the RegExpShared table from the compartment to the zone: when multiple iframes use the same regular expression, we will now only parse and compile it once (this matters for ads, Facebook like buttons, etc). I also fixed a performance bug with regular expressions and interrupts: we would sometimes execute regular expressions in the (slow!) regex interpreter instead of running the (much faster) regex JIT code.
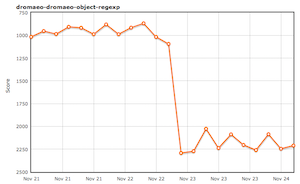
Finally, the RegExp constructor could waste a lot of time checking the pattern syntax. I noticed this when I was profiling real-world code, but the fix for this also happened to double our Dromaeo object-regexp score :)
Inline Caches
This year we finished converting our most important ICs (for getting/setting properties) to CacheIR, our new IC architecture. This allowed us to optimize more things, here are a few:
- I rewrote our IC heuristics. We now have special stubs for megamorphic lookups.
- We now optimize more property gets and sets on DOM proxies like
documentorNodeLists. We had some longstanding bugs here that were much easier to fix with our new tools. - Similarly, we now optimize more property accesses on
WindowProxy(things likethis.fooorwindow.fooin the browser). - Our IC stubs for adding slots and adding elements now support (re)allocating new slots/elements.
- We can now use ICs in more cases.
The work on CacheIR has really paid off this year: we were able to remove many lines of code while also improving IC coverage and performance a lot.
Property addition
Adding new properties to objects used to be much slower than necessary. I landed at least 20 patches to optimize this.
SpiderMonkey used to support slotful accessor properties (data properties with a getter/setter) and this complicated our object layout a lot. To get rid of this, I first had to remove the internal getProperty and setProperty Class hooks, this turned out to be pretty complicated because I had to fix some ancient code we have in Gecko where we relied on these hooks, from NPAPI code to js-ctypes to XPConnect.
After that I was able to remove slotful accessor properties and simplify a lot of code. This allowed us to optimize our property addition/lookup code even more: for instance, we now have separate methods for adding data vs accessor properties. This was impossible to do before because there was simply no clear distinction between data and accessor properties.
Property iteration
Property iteration via for-in or Object.keys is pretty common, so I spent some time optimizing this. We used to have some caches that were fine for micro-benchmarks (read: SunSpider), but didn't work very well on real-world code. I optimized the for-in code, rewrote the iterator cache, and added an IC for this. For-in performance should be much better now.
I also rewrote the enumeration code used by both for-in, Object.getOwnPropertyNames, etc to be much faster and simpler.
MinorGC triggers
In Firefox, when navigating to another page, we have a mechanism to "nuke" chrome -> content wrappers to prevent bad memory leaks. The code for this used to trigger a minor GC to evict the GC's nursery, in case there were nursery-allocated wrappers. These GCs showed up in profiles and it turned out that most of these evict-nursery calls were unnecessary, so I fixed this.
According to Telemetry, this small patch eliminated tons of unnecessary minor GCs in the browser:
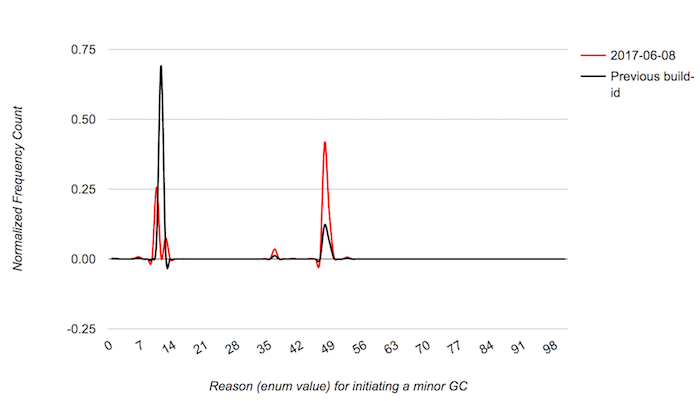
The black line shows most of our minor GCs (69%) were EVICT_NURSERY GCs and afterwards (the orange line) this just doesn't show up anymore. We now have other minor GC reasons that are more common and expected (full nursery, full store buffer, etc).
Proxies
After refactoring our object allocation code to be faster and simpler, it was easy to optimize proxy objects: we now allocate ProxyValueArray inline instead of requiring a malloc for each proxy.
Proxies can also have an arbitrary slot layout now (a longstanding request from our DOM team). Accessing certain slots on DOM objects is now faster than before and I was able to shrink many of our proxies (before these changes, all proxy objects had at least 3-4 Value slots, even though most proxies need only 1 or 2 slots).
Builtins
A lot of builtin functions were optimized. Here are just a few of them:
- I fixed some bad performance cliffs that affected various Array functions.
- I ported Object.assign to C++. It now uses less memory (we used to allocate an array for the property names) and in a lot of cases is much faster than before.
- I optimized Function.prototype.toString. It's surprisingly common for websites to stringify the same function repeatedly so we now have a FunctionToString cache for this.
- Object.prototype.toString is very hot and I optimized it a number of times. We can also inline it in the JIT now and I added a new optimization for lookups of the toStringTag/toPrimitive Symbols.
- Array.isArray is now inlined in JIT code in a lot more cases.
Other optimizations
- We unnecessarily delazified (triggering full parsing of) thousands of functions when loading Gmail.
- Babel generates code that mutates
__proto__and this used to deoptimize a lot of things. I fixed a number of issues in this area. - Cycle detection (for instance for JSON.stringify and Array.prototype.join) now uses a Vector instead of a HashSet. This is much faster in the common cases (and not that much slower in pathological cases).
- I devirtualized some of our hottest virtual functions in the frontend and in our Ion JIT backend.
Conclusion
SpiderMonkey performance has improved tremendously the past months and we're not stopping here. Hopefully there will be a lot more of this in 2018 :) If you find some real-world JS code that's much slower in Firefox than in other browsers, please let us know. Usually when we're significantly slower than other browsers it's because we're doing something silly and most of these bugs are not that hard to fix once we are aware of them.